Slack Group
Before we get started I have started a slack group dedicated to hacking. We welcome everyone from beginner to advanced to join. I will be on everyday answer questions, doing CTFs, and talking about cool hacks. If you enjoy hacking and are looking for like minded people join below:
NEW Hacking Group Slack Channel
Introduction
When performing a penetration test one of the first things I do is recon. After I identify all the domains and subdomains of a target I identify the paths that are on those endpoints. There are a number of ways to do this such as doing a directory brute force, using certification transparency logs, crawling the website, etc. In todays post I will demonstrate how to use the wayback machine to find interesting paths and vulnerabilities on a website.
Wayback Machine
The wayback machine is an archive of the entire internet. Basically they go to every website and they crawl it while taking screenshots and logging the data to a database. These endpoints can then be queried to pull down every path the site has ever crawled as shown below:
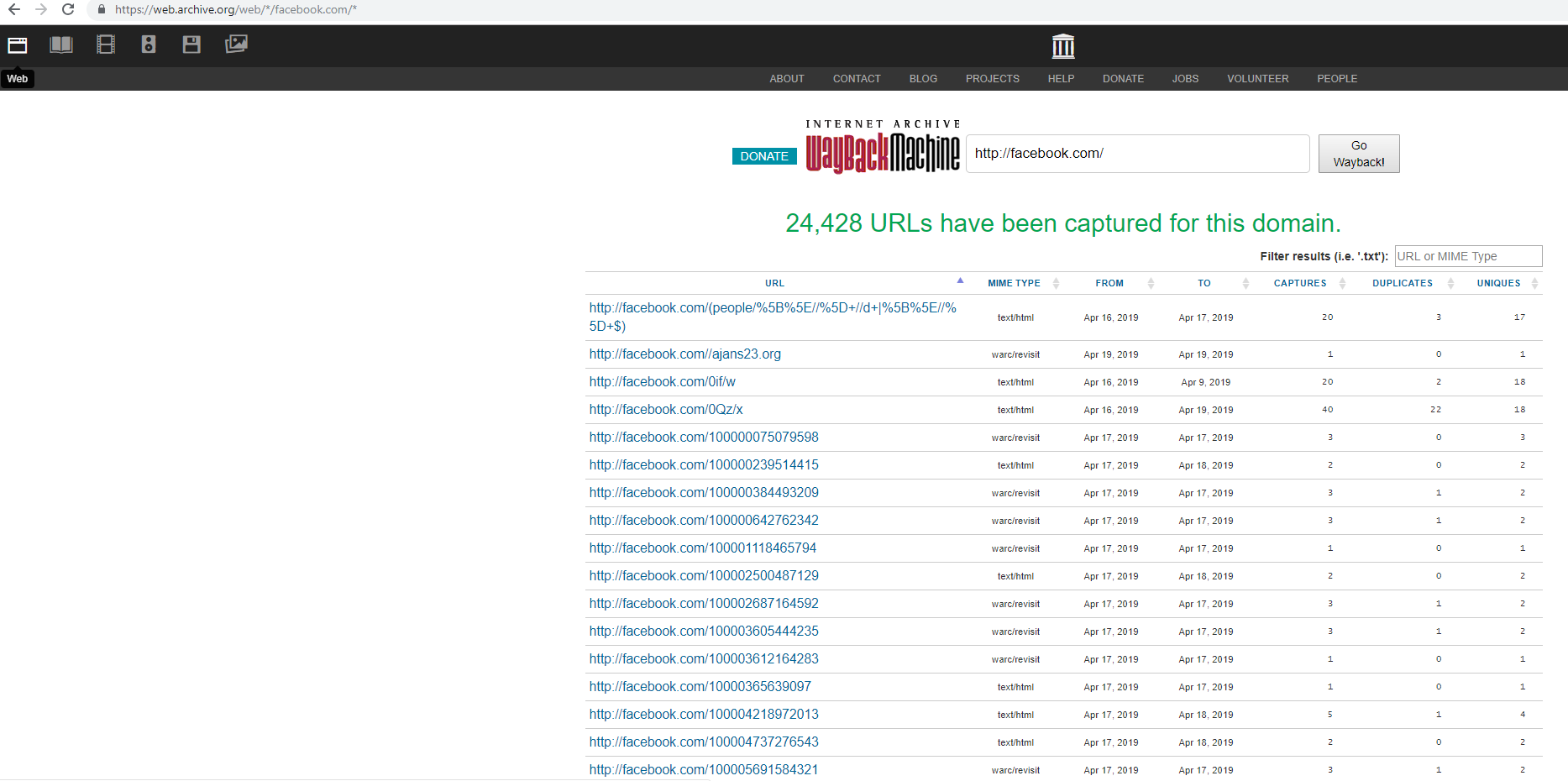
Going to “ https://web.archive.org/web/*/facebook.com/*” will pull down a list of paths that the wayback machine has crawled. We can then use the filter to search for specific files such as anything that ends in “.bak” as those might contain juicy backup information. Other interesting filters include:
- .zip
- .backup
- .config
- .csv
- /api/
- /admin/
Not only can you use this data to find interesting files but you can also find vulnerabilities by looking at the data. For instance if you see the path “example.com/?redirect=something.com” you can test for open redirects and SSRF vulnerabilities. If you see the GET parameter “msg=” you can test for XSS. The list can go on for days.
Tools
Some people like using the website to pull a list of paths but I prefer to use the command line. I created a small script that can be used to pull a list of paths from the wayback machine:ghostlulzhacks/waybackMachine
Contribute to ghostlulzhacks/waybackMachine development by creating an account on GitHub.github.com
You can then pipe the output to file and use grep to search for interesting files paths as shown below:
python waybackMachine.py facebook.com > facebookPaths.txt
cat facebookPaths.txt | grep “redirect=”
This will find any url that has the word “redirect=” in it. If you get any hits starts testing for vulnerabilities.
Conclusion
The wayback machine has a boat load of information. Before you decide to crawl a website yourself check out the wayback machine. It might save you a lot of time and effort by using other peoples crawled data. Once you get the data start looking for interesting files and GET parameters that might be vulnerable.